
A Xiaomi bemutatta a nyílt forráskódú, következtetésre specializált mesterséges intelligencia (MI) modelljét.
A MiMo névre keresztelt modellcsalád a következtetési képességek optimalizálásában hoz innovációt, mindezt viszonylag kisebb paraméterszám mellett.
Ez a technológiai óriás első nyílt forráskódú következtetési modellje, amely olyan kínai modellekkel versenyez, mint a DeepSeek R1 és az Alibaba Qwen QwQ-32B, illetve globális szereplőkkel, például az OpenAI o1 és a Google Gemini 2.0 Flash Thinking modellekkel. A MiMo család négy különböző modellt tartalmaz, amelyek mindegyike egyedi felhasználási esetre készült.

A MiMo sorozattal a Xiaomi kutatói a következtetési MI modellek méretproblémáját kívánták megoldani. A mérhető következtetési modellek általában körülbelül 24 milliárd vagy annál is több paramétert tartalmaznak. Ezt a méretet azért tartják fenn, hogy a nyelvi modellek kódolási és matematikai képességeit egyszerre és egyenletesen tudják javítani, amit nehéz elérni kisebb modellekkel.
Ezzel szemben a MiMo modell 7 milliárd paraméterrel rendelkezik, és a Xiaomi szerint teljesítménye megegyezik az OpenAI o1-mini modelljével, sőt felülmúlja több, 32 milliárd paraméterrel rendelkező következtetési modellt is. A kutatók szerint az alap MI modell 25 billió tokenen lett előképzett.
A kutatók szerint a hatékonyságot az adat-előfeldolgozási folyamatok optimalizálásával, a szövegkinyerő eszköztárak fejlesztésével és a többdimenziós adat-szűrés alkalmazásával érték el. A MiMo előképzése három szakaszos adatkombinálási stratégiát tartalmazott.
A belső tesztek alapján a Xiaomi kutatói azt állítják, hogy a MiMo-7B-Base modell 75.2 pontot ért el a BIG-Bench Hard (BBH) benchmark tesztjén a következtetési képességek terén. A zero-shot megerősítéses tanuláson (RL) alapuló MiMo-7B-RL-Zero modell kimagaslóan teljesít matematikai és programozással kapcsolatos feladatokban, és 55.4 pontot ért el az AIME benchmarkon, 4.7 ponttal megelőzve az o1-mini modellt.
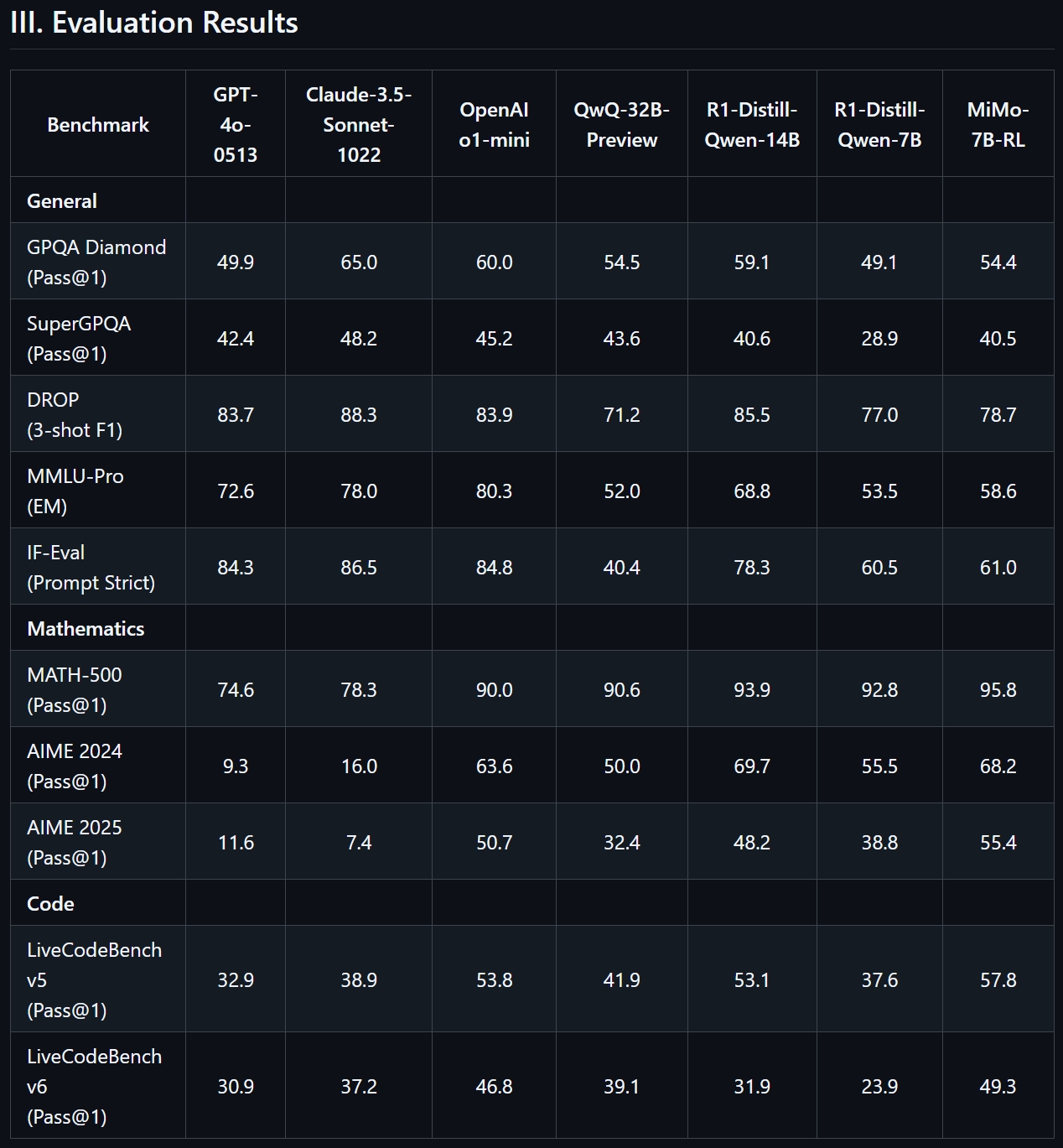
Mivel a MiMo nyílt forráskódú MI modell, letölthető a Xiaomi GitHub és Hugging Face oldalairól. A technikai dokumentáció részletezi a modell architektúráját, valamint az előképzési és utóképzési folyamatokat.
Ez egy szövegalapú modell, multimodális képességekkel nem rendelkezik. A legtöbb nyílt forráskódú modellhez hasonlóan, a pontos adatkészlet nem ismert.




